
GPT‑5 Is Releasing Soon: Facts You Should Know and Our Predictions on It
As generative AI enters another growth spurt, OpenAI’s next major model — GPT‑5 — has become the focus of intense speculation. Released models like GPT‑4.5 (also called “Orion”) already show chain‑of‑thought reasoning and use multiple tools, yet CEO Sam Altman has promised something far more unified and powerful. This article gathers everything that is currently known about GPT‑5, examines credible predictions about its abilities, and compares it with today’s strongest competitors such as Anthropic’s Claude 3 family and Meta’s Llama 3/3.1 models.
What is GPT‑5?
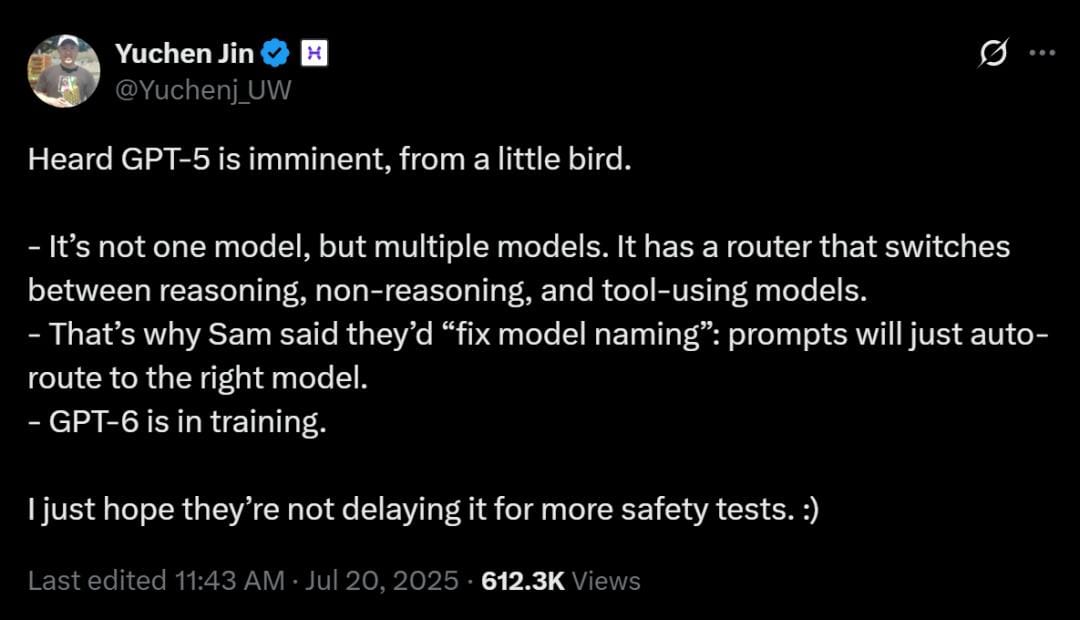
GPT‑5 will be OpenAI’s next flagship generative pre‑trained transformer. According to Altman’s February 2025 roadmap and later interviews, it will combine the GPT‑series with OpenAI’s experimental “o‑series” reasoning models to create a single system that automatically chooses how to think and which tools to call. The company wants to “return to magic unified intelligence” by eliminating the confusing model picker. GPT‑4.5 (Orion) is described as the last non‑chain‑of‑thought model; GPT‑5 will therefore integrate chain‑of‑thought reasoning and the o3 reasoning engine.
OpenAI’s posts also promise that GPT‑5 will work seamlessly across voice, image and text, integrate features like Advanced Voice Mode, Canvas, Search and Deep Research into one interface and automatically decide when to reason deeply or quickly. Free ChatGPT users will receive “unlimited chat access” at a standard intelligence level, while Plus and Pro subscribers will be able to run the model at progressively higher intelligence settings. The goal is to provide a single AI that “just works” for a wide range of tasks.
When will GPT‑5 be released?

As of late July 2025 there is no official release date. In February 2025 Altman wrote on X that GPT‑4.5 would arrive in “weeks” and that GPT‑5 would follow “within months”. He reiterated this in a June 18, 2025 podcast, saying he hoped GPT‑5 would be ready during the northern‑hemisphere summer of 2025. Tech news outlets therefore expect a July–September launch, but the company has not confirmed a day. Until an official announcement appears, all dates remain speculative.
Confirmed facts about GPT‑5
The following facts about GPT‑5 come directly from Altman’s roadmap and public statements.
- Unified model and chain‑of‑thought reasoning. GPT‑5 will be one model that merges the GPT‑series and o‑series. It will automatically decide when to engage in longer reasoning and will not ship o3 as a standalone model. GPT‑4.5 (Orion) is the last model without chain‑of‑thought reasoning.
- Larger context windows and persistent memory (likely). Leaked documents and internal tests hint at “Reasoning Alpha” prototypes with one‑million‑token context windows and unified memory. OpenAI has not confirmed final context limits, but the company is expected to substantially increase token capacity, enabling the model to handle long documents and remember more information.
- Improved reliability and reasoning. Altman told Bill Gates that GPT‑5 would improve reasoning and reliability; he highlighted multimodality (“speech in, speech out, images… eventually video”) and said the most important progress would be in reasoning ability. Reducing hallucinations is a key goal.
- Simplified product lineup. OpenAI will unify ChatGPT and its API under GPT‑5 and will drop the separate o‑series models.
5.Multiple intelligence levels. Free ChatGPT users will receive unlimited GPT‑5 access at a standard intelligence setting; Plus subscribers will get a higher level and Pro subscribers an even higher level. Altman said the goal is to deliver better answers by allowing the model to think longer when needed.
6.Tool integration. The new model will integrate voice, image and search tools (Advanced Voice Mode, Canvas, Search and Deep Research). These features will be built into the core system so users no longer have to select a specific mode
Predictions for GPT‑5
Could GPT‑5 become a super‑agent?
Experts interviewed by Senior Executive believe GPT‑5 will mark a shift from reactive chatbots to agentic AI. Sam Altman hinted that the model will include persistent memory and agentic behaviour. Divya Parekh, an AI strategist, expects true multimodal integration (text, image and audio) and is most excited about the evolution in reasoning and tool use. She predicts that persistent memory and adaptive behavior could push GPT‑5 into agentic territory where it can delegate tasks, interface with APIs and even orchestrate workflows autonomously. Another expert described the development as an “evolution from question‑answering to an autonomous agent that plans and executes”.
These predictions are speculative but align with OpenAI’s goal of enabling the model to decide how to think and which tools to use. If GPT‑5 can remember user preferences and execute multi‑step tasks, it will behave more like a super AI agent than a traditional chatbot. However, such agentic features may roll out gradually; early versions may still require human oversight to maintain safety.
Will GPT‑5 generate videos?
During a conversation with Bill Gates, Altman said that multimodality will extend beyond speech and images to “eventually video”. This suggests OpenAI is working toward video understanding and perhaps video generation. At launch GPT‑5 will likely integrate image‑editing tools like Canvas, but full video synthesis may come later. OpenAI’s separate “Sora” model already generates short videos, so merging that capability into GPT‑5’s toolkit is plausible. Users should therefore expect stronger image processing and some form of video support, but not necessarily Hollywood‑quality video generation on day one.
Want to try super model that can generate high quality videos?
How will GPT‑5 be stronger than GPT‑4.5?
Comparing facts and reasonable predictions, GPT‑5 should improve on GPT‑4.5 in several ways:
- Chain‑of‑thought reasoning. GPT‑5 will incorporate reasoning models (o3) and will know when to think longer or shorter. This should improve performance on maths, coding and complex multi‑step tasks that still challenge GPT‑4.
- Persistent memory and larger context. Rumoured one‑million‑token windows and unified memory will allow the model to retain more information and work across sessions. Such capacity would make GPT‑5 far better at projects like summarizing large documents or tracking long‑term conversations.
- Higher reliability and safety. OpenAI is targeting a reduction in hallucinations and better response consistency. Paid tiers will allow the model to reason longer, which should further improve answer quality.
- Multiple intelligence levels. Offering different levels of intelligence will let users choose how much “brainpower” to dedicate to a task, something GPT‑4.5 lacks.
Multimodal abilities and tool use. With built‑in voice, image and search tools, GPT‑5 will handle natural conversations, images and audio more seamlessly. It may eventually generate or interpret videos.
GPT‑5 vs Claude 3 vs Meta Llama 3/3.1
| Feature | GPT‑5 (anticipated) | Claude 3 family (Haiku, Sonnet, Opus) | Meta Llama 3/3.1 |
|---|---|---|---|
| Developer / License | OpenAI; proprietary. ChatGPT access through free, Plus and Pro tiers | Anthropic; proprietary but accessible via API and Claude.ai | Meta AI; open‑source models (Llama 3 8B & 70B, Llama 3.1 405B) for research and commercial use |
| Release timeframe | Expected summer 2025 but no official date | Claude 3 launched March 2024; Claude 4 released May 2025. | Llama 3 released April 2024; Llama 3.1 (405B) released July 2024. |
| Model size / architecture | Parameter count undisclosed; will unify GPT‑series and o‑series reasoning models. | Multiple sizes: Haiku (fast), Sonnet (balanced) and Opus (most capable). Anthropic does not publish exact parameter counts but says they outperform peers on many benchmarks. | Llama 3 released in 8B and 70B sizes; Llama 3.1 adds a 405B model. |
| Context window | Rumoured to be much larger — possibly hundreds of thousands or a million tokens. | Default 200K tokens; can handle over one million tokens for select customers. | Llama 3 has unspecified context; Llama 3.1 models offer 128K‑token context windows. |
| Multimodality | Confirmed support for text, images and speech; Altman hinted at eventual video support. Built‑in tools will include voice mode, canvas, search and deep research. | Strong vision: Claude 3 models can process images, charts and diagrams and offer near‑instant responses; they improve reasoning, content creation and code generation. | Llama 3 is text‑only at release but Meta plans multimodal models; Llama 3.1 remains text‑based with improved reasoning. |
| Reasoning and agentic features | Will include chain‑of‑thought and o3 reasoning; aims to reduce hallucinations. Experts predict persistent memory and agentic behavior. | Claude 3 Opus demonstrates improved reasoning, mathematics and logical reasoning, with reduced refusals. | Llama 3.1 shows improved reasoning, math, tool use and multilingual translation but lacks chain‑of‑thought capabilities. |
| Video generation | Altman said “eventually video,” suggesting that future versions may handle video. | Not currently capable of generating video. | Llama models are text‑only; video capabilities are not yet announced. |
| Availability / cost | Free ChatGPT users get unlimited GPT‑5 at standard intelligence; Plus and Pro tiers will offer higher intelligence levels. | Available via Claude.ai and API; pricing scales with usage. Haiku is optimized for speed, Sonnet balances capability, Opus is most powerful. | Open models can be downloaded and used locally or via API; licensing allows research and commercial use. |
Frequently Asked Questions
When exactly will GPT‑5 be released?
OpenAI has not announced an official date. Altman’s February 2025 roadmap said that GPT‑4.5 would ship in weeks and GPT‑5 in months. In June 2025 he said the company hopes to release it during summer 2025. Until OpenAI makes a formal announcement, treat any specific date as speculation.
Will GPT‑5 be free?
Yes — at least at a baseline. Free ChatGPT users will receive unlimited access to GPT‑5 at a standard intelligence level. Paid Plus and Pro subscriptions will unlock higher intelligence levels and likely faster access to new features.
What new features will GPT‑5 have?
Confirmed features include a unified model that integrates reasoning and tool use, chain‑of‑thought reasoning, multimodal input and output (text, voice, images and possibly video), and built‑in tools such as voice mode, canvas, search and deep research. The model will also deliver longer context windows and improved reliability. These set of tools are prefect for content creators and web designers looking to enhance their workflows.
Will GPT‑5 generate videos?
Altman said that multimodality will eventually include video. Early versions of GPT‑5 may not produce full‑fledged videos, but integration with tools like OpenAI’s Sora suggests that some level of video understanding or generation could be added in the future.
Is GPT‑5 artificial general intelligence (AGI)?
No. Altman and other experts caution that GPT‑5 will not achieve AGI. Instead, it represents incremental progress in reasoning, multimodality and tool integration. Even with persistent memory and agentic behavior, the model will operate within bounds set by its training data and safety systems.
How does GPT‑5 compare with Claude 3 and Llama 3/3.1?
Claude 3 models already provide long context windows (200K tokens, with million‑token capability) and strong reasoning over text and images. Llama 3.1’s 405B‑parameter model offers a 128K‑token context and is open source. GPT‑5 remains unreleased, but it aims to unify reasoning and tools, deliver even larger context windows and eventually add video support, albeit in a proprietary platform.
Conclusion
GPT‑5 is shaping up to be more than an incremental update. By unifying OpenAI’s disparate models, incorporating chain‑of‑thought reasoning and integrating multimodal tools, it could deliver a versatile AI that behaves more like a digital colleague than a chat interface. Persistent memory and agentic behavior may allow the model to remember, plan and execute tasks autonomously — a significant step toward AI assistants that handle complex workflows. Yet major questions remain about its release date, pricing details and how far video or agentic capabilities will go at launch. Until OpenAI reveals more, these predictions remain educated projections. For now, GPT‑5’s impending debut signals a new phase in AI development where unified intelligence and human‑like reasoning become the norm.