
Kling-Foley Review: Make an AI Video with Real-time Audio with Kling AI's New Multimodal Diffusion Transformer
You’ve seen those AI-generated videos, haven’t you? Those slick clips that look amazing, but the audio? It sounds like it was slapped together in a noisy garage. If you’ve ever thought, “There must be a smarter way to sync sound with AI videos,” you’re in good company. That’s exactly what Kling-Foley is here to address. In this article, we'll show you the details of AI video with real-time audio with Kling AI's new multimodal diffusion transformer. Here we go!
What is Kling-Foley?
Kling-Foley is a multi-step, multi-modal video-to-audio generation model at scale, which sounds complicated, but is really quite simple: This means that the model can generate high-fidelity stereo audio that is semantically matched to the video content, without the need of manual sync or professional editing tools.
Kling-Foley uses video content along with optional text prompts to create authentic audio that matchs with each clip in a completely frame-accurate way. We're talking about sound effects, background music, ambient noise-you name it. It uses spatial sound modeling, which means it knows how to position a barking dog or crackling fire in a multi-dimensional space. If you've ever been upset with syncing, clipping, or entirely too generic soundbeds, Kling-Foley is designed for you.
Why Kling-Foley is A Breakthrough for AI Video Generation?
From: https://www.arxiv.org/abs/2506.19774
AI-generated video has been a reality for more than two years now. But when it comes to sound? That’s still a bit of a weak link. Most creators are stuck manually adding voice-overs or background music, which can be a real time-suck. Early attempts to fix this problem relied on text-to-audio (T2A) models. While they’ve been somewhat effective, they come with a major limitation: they don’t actually “see” the video. This often leads to mismatched sound and visuals—like hearing footsteps when no one’s walking or thunder when there’s no storm in sight.
Video-to-audio (V2A) modeling is rewriting the playbook. Kling-Foley goes beyond mere speculation about fitting sounds; it actively watches, understands, and interacts with the video content. What’s the tough part? Creating a model that can learn from video, audio, and text all together in one comprehensive dataset. Kling-Foley meets this challenge directly by launching a new evaluation benchmark—Kling-Audio-Eval—that sets a high standard for what’s to come.
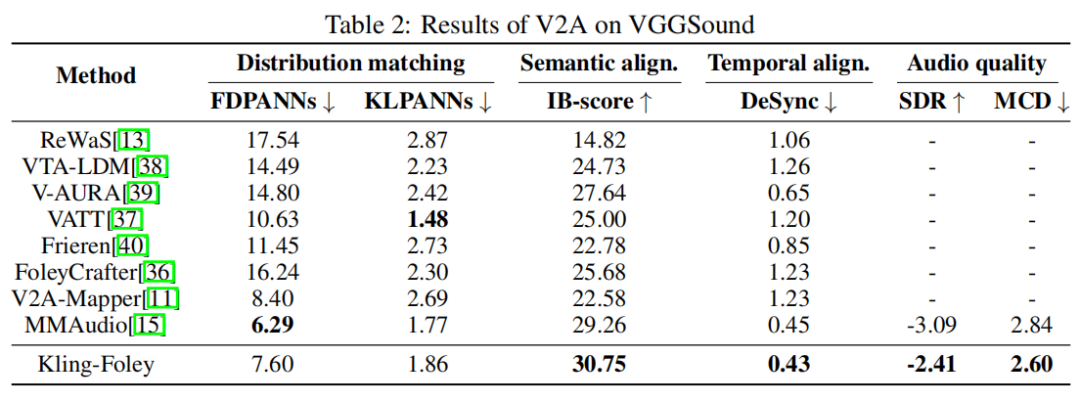
From: https://www.arxiv.org/abs/2506.19774
When comparing benchmarks across common public datasets, it beats the most competitive leaders in the industry on three important metrics, semantic align, temporal align, and audio quality. Regardless of whether we are looking at sound effects, instrumental music, spoken voice, or singing, Kling-Foley is always ranked at the top or very near the top.
How Did Kling-Foley Make Video-to-Audio Come True?
If you've ever attempted to manually sync audio to a video, you know it's a bit like trying to conduct an orchestra without a score. Kling-Foley changes all that, by incorporating powerful multimodal modeling into the picture—video, audio, and text all communicating in real-time.
Cross-Modality Interaction: Video, Audio, and Text in Sync
From: https://www.arxiv.org/abs/2506.19774
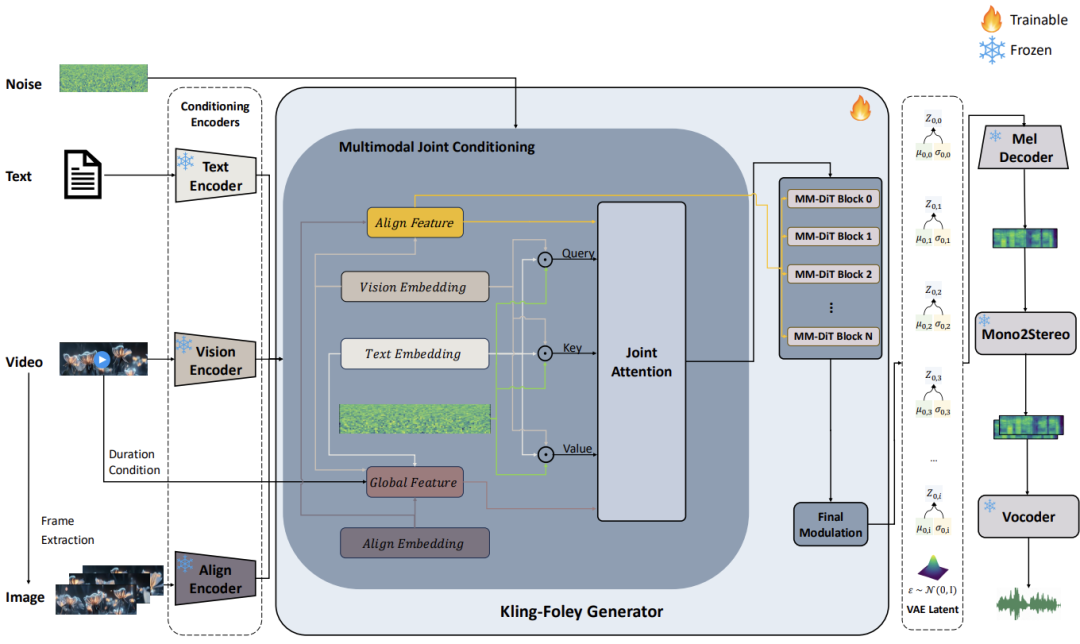
Kling-Foley's magic begins with a multimodal flow-matching architecture. The model takes video frames, text prompts (if needed), and timing information as inputs while generating the audio. These inputs are combined in a joint multimodal conditioning module. The magic continues within the MM-DiT (multimodal diffusion transformer) block that predicts VAE latent representations and uses an advanced design inspired by Stable Diffusion 3.
These are now transformed into a monaural Mel spectrogram, then stereo using spatial rendering, before being turned into a waveform by the vocoder. To ensure every squeak, splash, or footstep lands right on time, the model integrates a visual semantic module and a cross-modal alignment module. Together, they keep your sound synced at the frame level, enhancing realism and coherence like never before.
From Scratch: Building the Multimodal Dataset
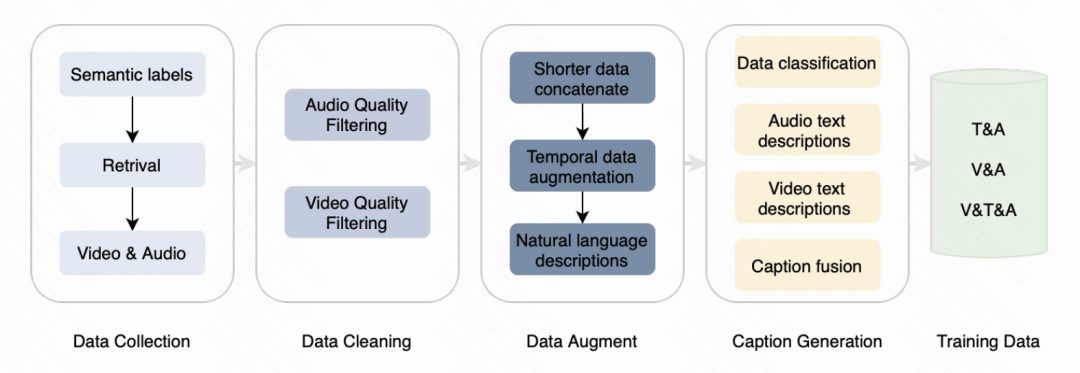
From: https://www.arxiv.org/abs/2506.19774
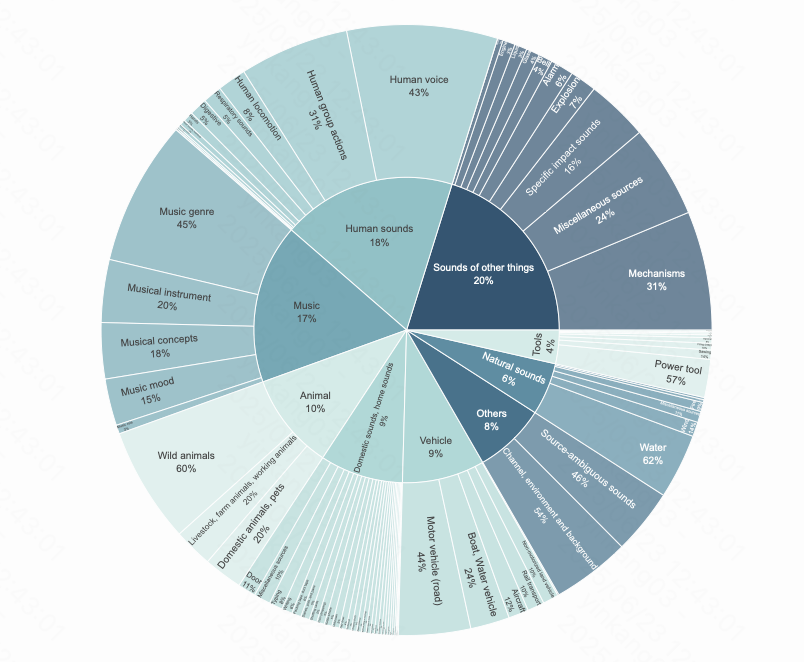
Kling-Foley didn't just pluck its capabilities out of thin air; it was trained on a rich dataset that was diverse and purposefully designed to model real-world audiovisual events. This dataset encompasses synchronously observed video, carefully labeled audio tracks, and pertinent text annotations. These richer multimodal inputs enable Kling-Foley to generalize based across a variety of scenes, from city traffic to underwater stillness, with realistic nuances.
A graphical examination of its sound label distribution demonstrates coverage of almost every type of acoustic scene imaginable: human activities, wildlife, machines, vehicles, and the outdoors. It is this diversity that allows Kling-Foley to create sound that seems alive and fits almost any context in which you can place it.
How Users Are Reacting to Kling-Foley(from X)
From X User @ Artedeingenio
- "Had a start frame but no end frame. Had to edit clips together. Edit is not as smooth as I'd like. But working on it. I love creating sound effects. I think I'm a Foley Artist at heart."
- "Wonder where Kling 2.1 will score. I think audio will be in the next version of these services, already see decent foley."
- “I paired it with a fast-paced animation, and the sound effects matched the action beat for beat. It felt cinematic.”
- “I used Kling-Foley to add audio to a scene with rain, passing cars, and a dog barking in the distance. It not only understood the environment but layered the sounds naturally. Very impressive.”
Generate AI Videos with Real-Time Audio with Kling-Foley in Deevid AI
Here’s some fantastic news: Deevid AI has integrated with the Kling-Foley model! This means you can whip up stunning AI videos with real-time, high-quality audio—and yes, you can try it out for free! No complicated setup, and no messy syncing to worry about.
What is Deevid AI?
Deevid AI turns your text, images, or video prompts into high quality videos in simple prompts. Whether you're looking to add a few interesting effects, change the whole feel, or even change your whole style of video, Deevid AI makes it super easy.
- Key Features
- Text to Video AI
- Image to Video AI
- Video to Video AI
- Popular Video Templates (AI Bikini Generator, AI Kissing, AI Hug, AI Handshake...)
- Pros
- Go to extraordinary video creation and develop studio-quality results in just one minute.
- Create compelling videos that grab attention on any platform and are clear and crisp on every device.
- No editing experience is necessary to create top-quality, professional-looking videos.
Use Cases of Kling-Foley
- AI-Generated Short Films: Kling-Foley allows independent creators to produce short films, with real-world-sounding environments, without the need to hire sound engineers.
- Animated Explainers and Educational Videos: Kling-Foley will provide contextual sounds, like rustling paper or typing keyboard sounds, adding more depth to the video to keep learners engaged and focused.
- Social Media Content: Speed is the name of the game on social platforms! Kling-Foley allows users to build catchy short fragments that connect sounds to scenes and don't require any editing timelines.
- Game Design Prototypes and Cinematics: Looking for a way to enhance your game design prototypes and cinematics? Kling-Foley has got you covered with spatial sound that immerses players in the world.
- Marketing & Product Videos: Whether you're highlighting a coffee machine or a hiking backpack, realistic sound effects can really elevate the experience. Kling-Foley makes your product demos feel more authentic and polished.
- Storyboarding and Pre-Production Sound Demos: Incorporate Kling-Foley in your early drafts to pitch your vision with sound already in the mix. Your clients and collaborators will be able to “hear” the scene come alive.
Will Kling-Foley Be A Genuine Threat to Hollywood Voice-over Artists?

To be clear, Kling-Foley has not yet got their sights on the A-list tier of Hollywood voice talent. But for many creators that are typically looking for just good audio, properly synchronized with their AI-generated visual, it is a time-saver. By automating sound effects, ambient audio, and tones of audio atmosphere, it also lowers the threshold for entry-level voice talent, or removing costly hours in the editing bay. It means that small teams or solo creators can now produce content that sounds like it came from a recording studio, even if it came from a bedroom.
That said, Kling-Foley is still a work in progress. It really shines in short, straightforward scenes. However, it does have some trouble with more complex physical processes, maintaining timing coherence beyond 20 seconds, and niche scenarios like sci-fi weaponry or underwater sonar. These gaps suggest that human expertise isn’t going extinct anytime soon—but the standards for AI-generated sound are definitely rising. As these models advance, even professional sound designers might begin to see Kling-Foley as a creative ally instead of competition.
FAQs
Q1: Can I use Kling-Foley for commercial projects?
Yes, you can. Just be sure to check the licensing terms. It’s designed to be creator-friendly, but you’ll want to confirm the usage rights based on your platform.
Q2: Does Kling-Foley support voice generation too?
Not really. Its main focus is on ambient sounds, sound effects, and music that syncs with visuals. However, if you pair it with a voice model, you can create a complete setup.
Q3: How long of a video can I use?
Kling-Foley can handle videos of different lengths, but it works best with clips under 30 seconds for now. They’re working on supporting longer videos in the future.
Q4: Can I combine it with other tools like Deevid AI?
Absolutely. Kling-Foley takes care of the sound, while Deevid handles the visuals. Together, they create a comprehensive AI production suite right at your fingertips.
Related Readings
If you enjoyed this review and want to explore more, check out: